Analysis of UFC statistics. Part 1: Web Scraping

As a huge martial arts and data nerd, I wanted to make a data exploration project about UFC statistics. The UFC, for context, is the biggest mixed martial arts promotion in the world. At the start of this journey, I had two choices two make. First, what data I was going to explore. Second, where I was supposed to gather the data.
The first question had a straightforward answer: I am going to analyze data of UFC fights and events. The second question required a bit more thinking. Sure, I could have easily downloaded the data from Kaggle. That would leave me without the opportunity to showcase my web scraping skills, though. Hence, I decided to crawl the data from the UFC Stats website.
This is the start of a 3-part series about extracting and analyzing data of (almost) every UFC fights and events. Part 1 explains technically how I scraped the data from the UFC Stats website. Part 2 and 3 will focus on the most interesting questions I could answer about UFC events (part 2) and fights (part 3). Now let’s see exactly what data I needed and how I extracted it.
Understanding the structure of the UFC stats website
First, it is necessary to understand the structure of the website, as well as the organization of the data. The website lists every UFC event, and every list item has a link to the details of the event. Then every event page has the statistics for all fights that took place in the event. The page also has the date and location of the event.
Checking the HTML structure
Now, when inspecting the website, I found extracting the data would be a bit trickier than expected. Both the events page and the page for each event have an HTML table structure. Furthermore, in the page for a specific event, each row represents a fight, and each table cell contains up to two data points.
Not only that, but the table cells may also contain icons indicating whether a fighter received a performance bonus, or whether a fighter was champion. Anyway, the information I wanted to gather is in text format, and nested inside <p> tags inside <tr> tags. Thus, I had an idea on how to access the texts I wanted. Now I need to actually start coding.
Setting up the project
When it comes to web scraping, there are multiple choices in terms of Python libraries and frameworks. I choose Scrapy because it makes it easy to crawl nested web pages. Additionally, it is easy to host a Scrapy project in the cloud thanks to scrapy cloud.
What I had to do now was starting a Scrapy project. I first created and activated a virtual environment using venv, and then installed Scrapy with pip install scrapy. Then I just used the command scrapy startproject ufc_scraper, reorganized the folder and initialized a Git repository. I ended up with this folder structure.
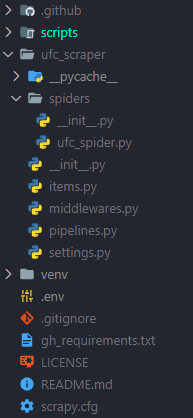
The scripts and .github folders are for automating the scraper runs (more on that later). For now, let’s focus on the spiders folder, and specifically, on the ufc_spider.py file.
Building the spider
Configuration
Before building a spider, let’s define what a spider is. This definition comes from the Scrapy docs.
Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). In other words, Spiders are the place where you define the custom behavior for crawling and parsing pages for a particular site (or, in some cases, a group of sites).
A spider is a Python class, which inherits from the Spider class (from the Scrapy module). Spiders must have two required properties: name and start_urls. The start_urls property specifies in which URLs the spider will start crawling data. Also, spiders can have another property called custom_settings, where you specify, among other settings, how the data is saved after scraping.
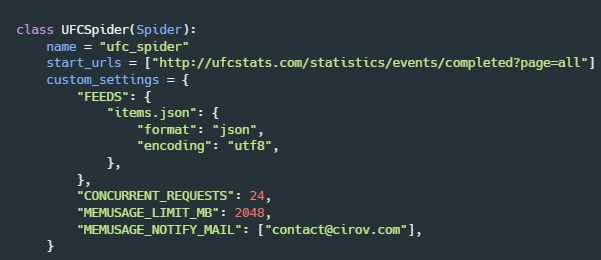
The FEEDS property is the one in which we set the saving format. In this case, I am saving the data as JSON, a format which is convenient for storing data in different nesting levels.
Parsing the data
Spiders must have a method called parse, which receives a response object. When we run the scraper, the response object contains the data requested from the websites in start_urls. The response object also has methods like xpath and follow. We use xpath to query the data we need from the response object. The follow method allows us to send a request to nested web pages.
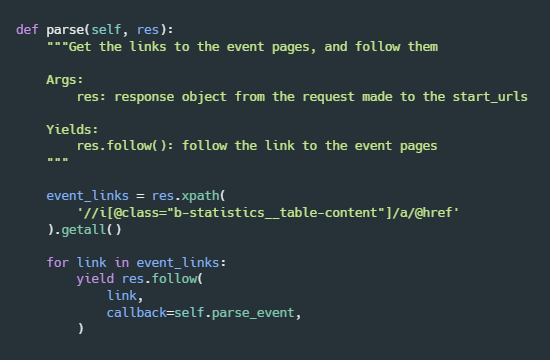
In the parse method, I use the xpath method to get the links to the event details page for each event. Then I iterate through the event links, and call the follow method on each link. Note that the follow method received a callback argument. This callback (called parse_event) will be executed per each request to each event details page.
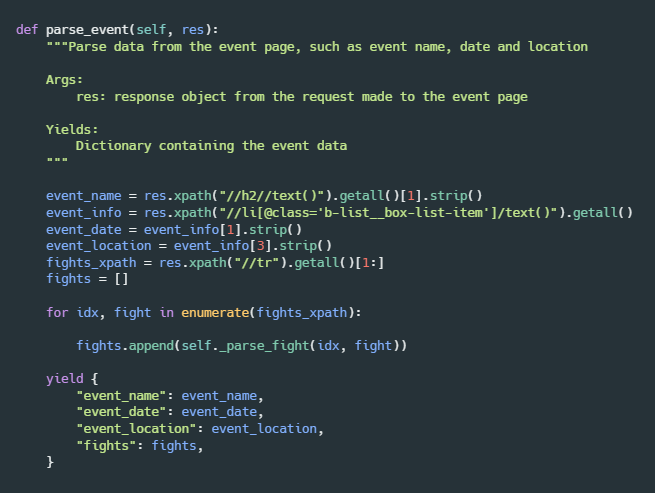
The parse_event method extracts the information about the event, such as the name of the event, its date and location. Moreover, parse_event extracts a list containing the rows (tr elements) that correspond to every fight in the event, and stores the list in the fights_xpath variable. Then it iterates through the list of rows, and appends the returned value of the _parse_fight method (which will be explained next) to the fights list. Lastly, parse_event yields a dictionary with the event information.
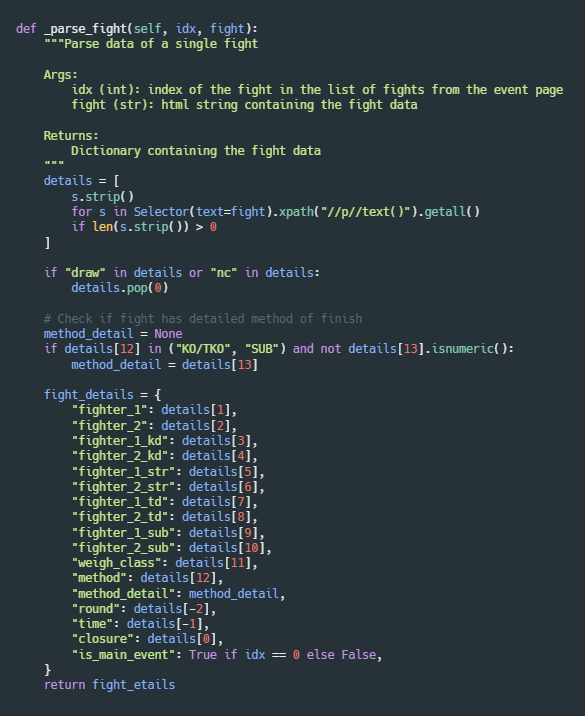
Similarly, the _parse_fight method receives a row containing the data of a specific fight. Then it extracts all the text content from the row and puts it into a “details” list. This list will contain the details of the fight (in a very specific order), such as the names of the fighters, how long the fight lasted, how many strikes were thrown, etc. Lastly, the _parse_fight method returns a “fight_details” dictionary, which contains the same data from the “details” list but with keys.
Automating the scraper
Great. The spider is ready, and the scraper works in my local machine… How do you put a scrapy project in a production environment, though? Also, how do you run the project on a certain schedule?
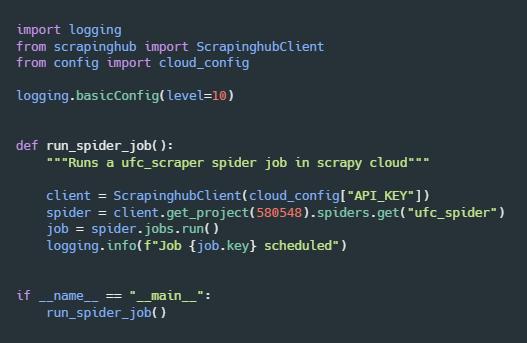
The easiest answer to the first question is scrapy cloud. Scrapy cloud provides a simple interface so that you deploy your scraper from a GitHub repo. Furthermore, a Python library called scrapinghub provides a client interface to connect to scrapy cloud. This library allows you to run your scraper in the cloud programmatically. Here is a simple script that uses scrapinghub to run the ufc spider.
As for the second question, the most common answer (in the data engineering world) would be Apache Airflow. However, I think for this project, using Airflow is like a killing a mosquito with a cannonball. Hence, I thought running a GitHub Actions workflow on a schedule was the best solution.
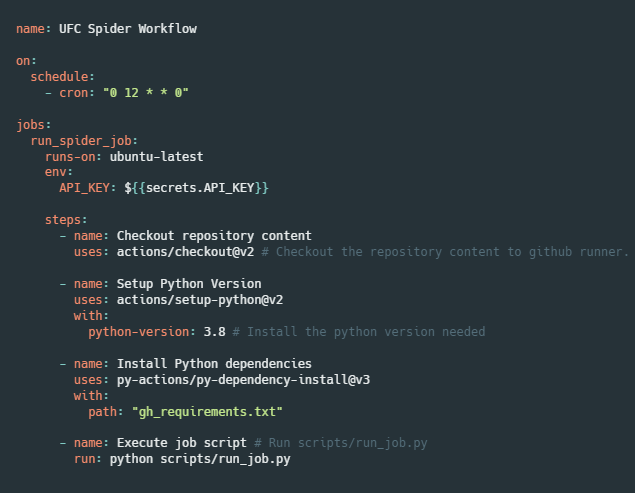
Using GitHub Actions, I run the project each Sunday at 12 pm UTC. This is because there is a UFC event roughly every Saturday night. The stats’ website gets updated shortly after. Below, you can see the workflow configuration.
Conclusion
Scraping a website can always be a challenge. Websites can have different HTML structures, and the UFC stats website is not an exception. It was certainly difficult to obtain the data I wanted, given the structure of the stats’ website. Thankfully, I did not encounter any roadblocks when trying to scrap the data.
Stay tuned for part 2 of this series. I promise it won’t be nearly as technical as this one.